
DHQ: Digital Humanities Quarterly 2014 | Volume 8 | Number 4
This paper was published in 2014 by three researchers at University of Wisconsin-Madison, focusing respectively on cinema and television (Hoyt), computational approaches (Ponto), and visualization and storytelling (Roy). It introduces ScripThreads, a new tool for digital analysis and visualization of screenplays and discusses some of the initial research findings from using ScripThreads on hundreds of screenplays from the American Film Scripts Online collection. Most of the paper is dedicated to models for close reading by analyzing and comparing two screenplays co-written and directed by Lawrence Kasdan, The Big Chill (1983) and Grand Canyon (1991), and distant reading “by searching across hundreds of screenplays for the pattern of the “hyper-present protagonist” — movies that place a main character in every scene or nearly every scene.”
The inspiration for ScripThreads came from movie narrative charts, an info-graphic published on the xkcd.com website, which hilariously visualized character interactions in films, and subsequent attempts to build an algorithmic approach to generate these types of visualizations. The authors found that of the “several shortcomings” of later algorithms (produced by Tanahashi & Ma) one of the most important was that all the information needed to be gathered externally, requiring for the data to be collected and investigated (analyzed) beforehand. This presents an important limitation to researchers in the growing field of scriptwriting research, especially when looking to compare hundreds of scripts. Their proposed intervention is a visualization tool that is capable of analyzing the text beforehand.
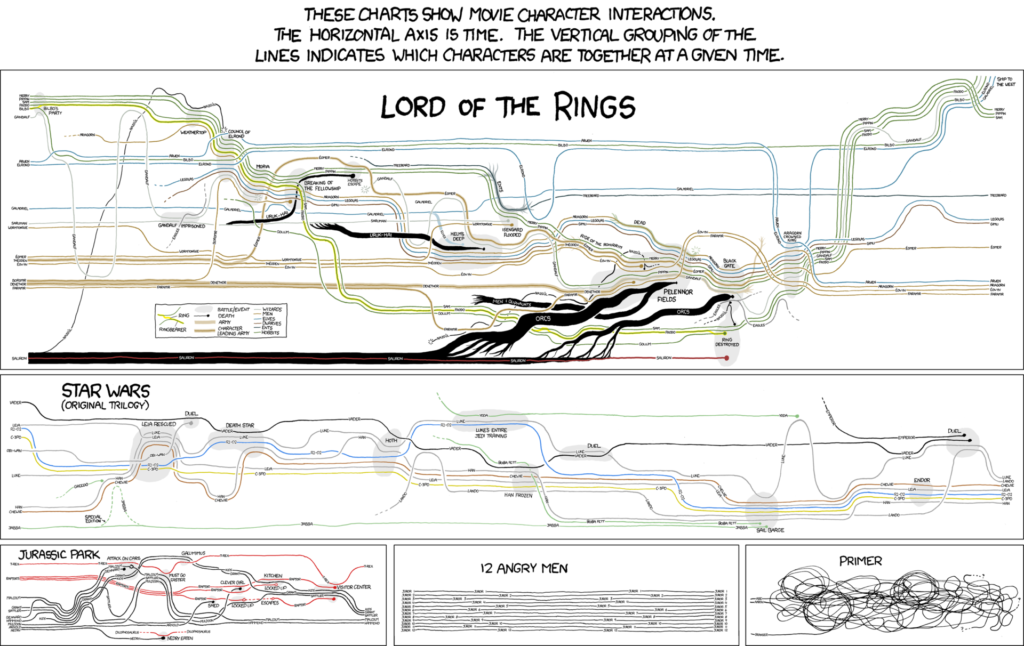
ScripThreads was written in C++ and it employs both a supervised and an unsupervised approach to textual analysis. It is “trained” to identify characters and scenes, and the length and numbers of appearances in any given script. It first runs through screenplay lines to determine if they indicate a character, and then marks the beginning and end of a scene, and generates data for each scene identifying the characters present, and the length of each scene in relation to length of script. This data then produces four different types of visualizations marking character connectivity, presence, absence, and the option to export a CSV with character and scene statistics.
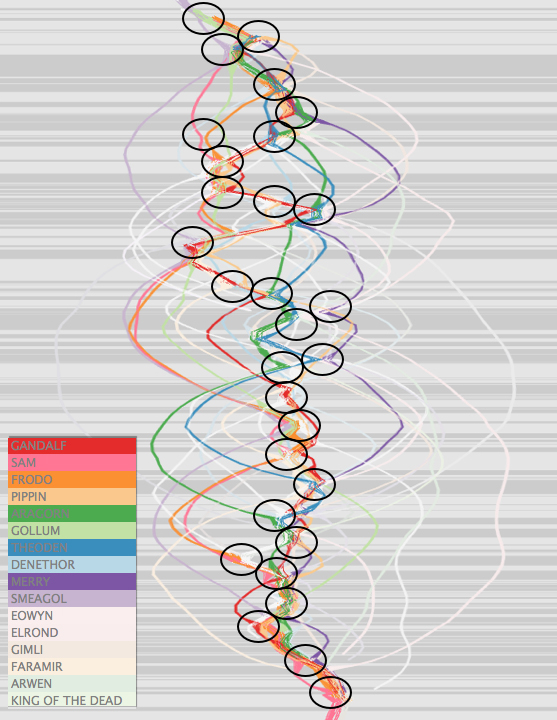
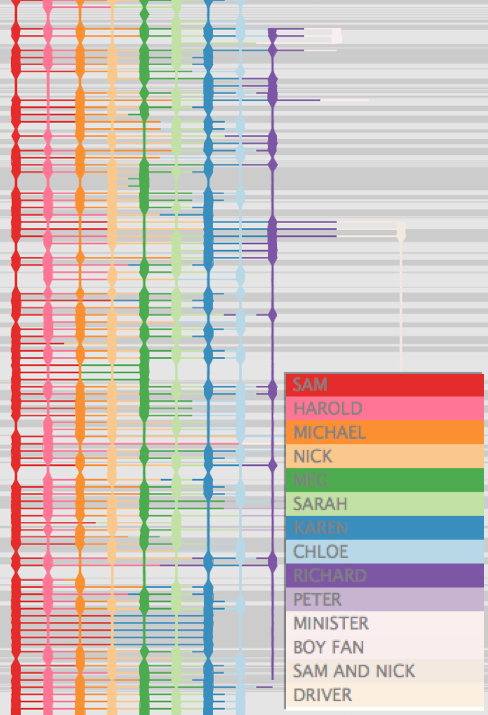
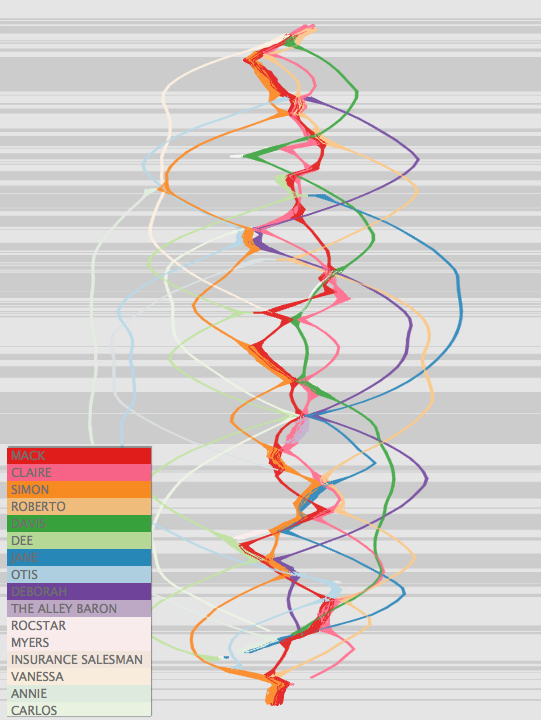
Most of the paper is dedicated to models of visualization extensive analysis presenting a case study for each visualization in an effort to convince that the tool enhances close reading and facilitates distant reading of screenplays. The paper analyzes two Lawrence Kasdan films using visualizations by ScriptThreads, focusing on the film Grand Canyon as a case study. The graphs reveal several patterns, such as the centrality of a character and presence of female characters. The latter is confirmed in each type of visualization produced. The Distant Reading Case Study reveals historical and genre patterns of the “hyper-protagonist” that confirm and challenge existing works.
I downloaded the ScripThreads prototype to parse and visualize a few screenplays I found online, but I was unsuccessful. The limitations of my technical skills are probably just as responsible as the glitches in the prototype, but there are currently two versions of ScripThreads on the site that seem to have attempted to address errors. This suggests that the project might still be active. I selected this piece hoping that it would allow for quick analysis and visualization of a large corpus of screenplays. What I found is that ScripThreads is too limited for such an analysis. As the authors write, it is meant to enhance close and distant reading of scripts, ideally along several other existing tools. There are limitations to ScripThreads even as a visualization tool. Although it parses text, it can only identify scenes and characters and each script needs to be run individually. I think the analysis that the tool facilitates is very specific and might all have already been covered in this article.

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.