Feminist commentary on text analysis tends to focus on the technical aspects of the work: data collection and processing, algorithms, and the visualization of results. However, most of the literature seems to start with the assumption that researchers already know how to write their research questions. Unfortunately, several case studies prove the contrary: text analysis projects that do not start with the right questions end up being flawed in all the other phases, with problems ranging from bias in data collection and inaccurate statistics to outright sexist conclusions. Research questions are at the core of a text analysis project and they influence every other phase, but there is actually little guidance on how to craft them.
In my paper, I argue that a feminist text analysis is possible and that it must start with well-thought, well-framed research questions. These must be rooted in a feminist praxis, an impetus towards action, and a realistic conception of what artificial intelligence can do.
I will create a framework to guide scholars in their formulation of research questions for their text analysis projects. To do so, I will draw from our readings from this semester, my Jupyter notebook projects, and examples of text analysis that we examined for this class. Rather than creating restrictive parameters, my framework will be a set of guidelines that feminist scholars can use to orient themselves at the very beginning of their research project, so that they can start asking the right questions.
DHQ: Digital Humanities Quarterly 2014 | Volume 8 | Number 4
This paper was published in 2014 by three researchers at University of Wisconsin-Madison, focusing respectively on cinema and television (Hoyt), computational approaches (Ponto), and visualization and storytelling (Roy). It introduces ScripThreads, a new tool for digital analysis and visualization of screenplays and discusses some of the initial research findings from using ScripThreads on hundreds of screenplays from the American Film Scripts Online collection. Most of the paper is dedicated to models for close reading by analyzing and comparing two screenplays co-written and directed by Lawrence Kasdan, The Big Chill (1983) and Grand Canyon (1991), and distant reading “by searching across hundreds of screenplays for the pattern of the “hyper-present protagonist” — movies that place a main character in every scene or nearly every scene.”
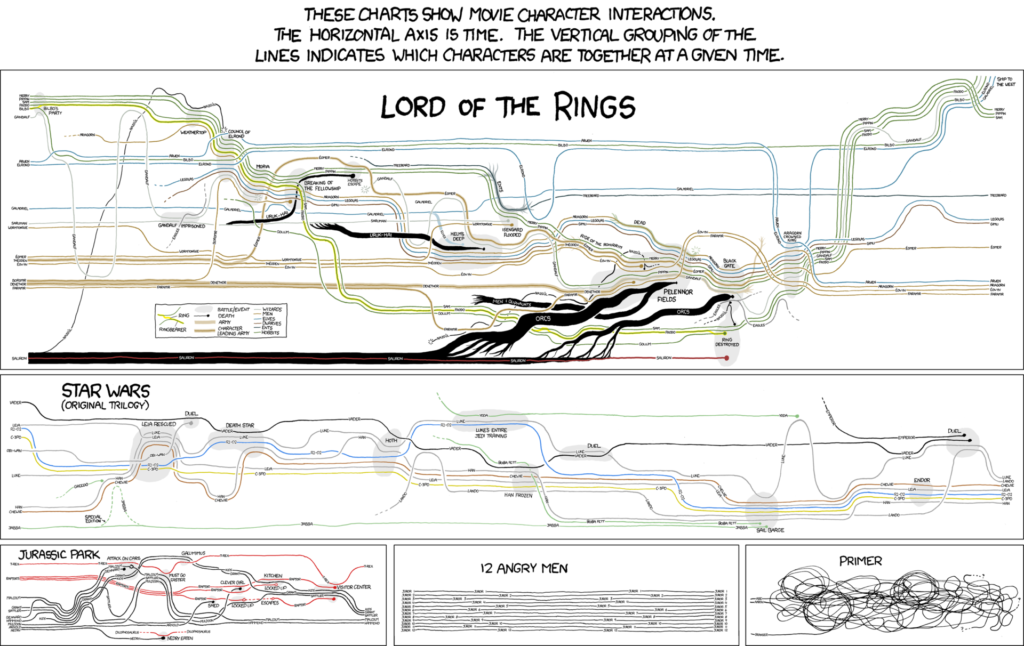
The inspiration for ScripThreads came from movie narrative charts, an info-graphic published on the xkcd.com website, which hilariously visualized character interactions in films, and subsequent attempts to build an algorithmic approach to generate these types of visualizations. The authors found that of the “several shortcomings” of later algorithms (produced by Tanahashi & Ma) one of the most important was that all the information needed to be gathered externally, requiring for the data to be collected and investigated (analyzed) beforehand. This presents an important limitation to researchers in the growing field of scriptwriting research, especially when looking to compare hundreds of scripts. Their proposed intervention is a visualization tool that is capable of analyzing the text beforehand.
ScripThreads was written in C++ and it employs both a supervised and an unsupervised approach to textual analysis. It is “trained” to identify characters and scenes, and the length and numbers of appearances in any given script. It first runs through screenplay lines to determine if they indicate a character, and then marks the beginning and end of a scene, and generates data for each scene identifying the characters present, and the length of each scene in relation to length of script. This data then produces four different types of visualizations marking character connectivity, presence, absence, and the option to export a CSV with character and scene statistics.
Most of the paper is dedicated to models of visualization extensive analysis presenting a case study for each visualization in an effort to convince that the tool enhances close reading and facilitates distant reading of screenplays. The paper analyzes two Lawrence Kasdan films using visualizations by ScriptThreads, focusing on the film Grand Canyon as a case study. The graphs reveal several patterns, such as the centrality of a character and presence of female characters. The latter is confirmed in each type of visualization produced. The Distant Reading Case Study reveals historical and genre patterns of the “hyper-protagonist” that confirm and challenge existing works.
I downloaded the ScripThreads prototype to parse and visualize a few screenplays I found online, but I was unsuccessful. The limitations of my technical skills are probably just as responsible as the glitches in the prototype, but there are currently two versions of ScripThreads on the site that seem to have attempted to address errors. This suggests that the project might still be active. I selected this piece hoping that it would allow for quick analysis and visualization of a large corpus of screenplays. What I found is that ScripThreads is too limited for such an analysis. As the authors write, it is meant to enhance close and distant reading of scripts, ideally along several other existing tools. There are limitations to ScripThreads even as a visualization tool. Although it parses text, it can only identify scenes and characters and each script needs to be run individually. I think the analysis that the tool facilitates is very specific and might all have already been covered in this article.
This week, I examined Fleshing Out Models of Gender in English-Language Novels (1850 – 2000) by Jonathan Y. Chen. This piece interestingly examines a semi-literal sort of “fleshing-out” – that is, Cheng discusses how anatomy factors into characterization and the presentation and representation of characters, and the relationship between this and gender. Cheng also examines how models of gender have changed over the 150 years proceeding 1850 and addresses notions of heteronormativity and binary gender.
In his introduction, Cheng writes that “it is difficult to overstate the significance of the body in scholarly accounts of gender” but that “[anatomical] details have long played a larger role in the representation of women” (Cheng 2-3). He also comments that “[anatomical] characteristics have increasingly been deployed along gendered lines until only very recently” but that “men and women are increasingly embodied using different words,” to the point of descriptions of actions such as “clasping one’s hand” are indicative of gender (Cheng 3). In brief, Cheng asserts that as time goes on, anatomical descriptions become more common in writing.
In his second section, titled Methods and Limitations, Cheng uses a modified version of BookNLP, a natural language processing pipeline, to perform what is largely supervised text analysis of the works in his corpus (clearly stated to be over 13000 English language novels on page 7). He posts images of several samples of his process, including an array depicting locations of references to a character in text (in terms of page number), the pronouns or proper nouns that those references consist of, and the way those references are tied back to the character in question. Cheng describes “[adding] onto [characters’ models] by extracting additional words that physically describe each character” and “[gathering] the verbs and adjectives modifying their bodily features” (Cheng 4).
Essentially, Cheng attempts to associate verbs and adjectives with parts of the body, and then associate all of those and their combinations with a gender. Cheng gives the example of the phrase his hands compared to the phrase his hands grasped: in this case, the verb “grasp” would be associated with the noun “hands” and both words, as well as the combination of the two words, would be associated with the male gender. Of course however, his results use the entire corpus. If he were to encounter three instances of “her hands grasped” later on, it would shift the words towards femininity for the purposes of the analysis.
In terms of limitations, Cheng mentions that “labelled as either feminine, masculine, or unknown” isn’t sufficient to “capture the complexity of gender identity” (Cheng 6). However, he takes into account that his corpus includes works from a time of much more rigid gender norms, thus almost using this limitation to his advantage. Additionally, he admits that pronouns such as “I,” especially in a vacuum, are not sufficient to present a clear gender identity. As a result, he is unable to count such characters’ physical features in a matter applicable to his study.
In the section entitled Embodying Fictional Men and Women, 1850 – 2000, Cheng displays graphs of his results, depicting a trend he describes as “body language [becoming] a growing aspect of all characters as we get closer to the twenty-first century” – on one table of results, the slope (“shown to provide sense of rate of increase”) of the data covering the percentage of physical description of men over time is over double that of the percentage of physical description of women over time (Cheng 9). Later, he posts two graphs comparing the use of body language by gender of characters, but segregated by the gender of the writer of the pieces. Interestingly, both of these graphs show the same general trend as the first graph. However, Cheng comments that “the correlation has dropped a fair amount for female characters written by women” – he keeps in mind the possibility of this being because of a reduce sample size, but comments that there could be “a less poignant relationship between historical progression and the amount of physical description attributed to women”(Cheng 14-15).
Cheng’s last sections before his conclusion are Gendering the Body and Transformations of the Gendered Body. The former presents a very interesting graph showing the accuracy to which text analysis models can predict gender from physical description of texts from given years. While showcasing a lack of accuracy from the model may seem counterproductive without context, Cheng does so to make an intriguing point – at some points in history, specifically towards either end of the 1850-2000 range, gender was harder to predict from physical description. This is supported by the graph showing the least accuracy to the extremes of the X-axis, and the most accuracy towards the middle-right, around 1955.
In his conclusion, Cheng admits that he “[doesn’t] want to make it seem like [he has] provided a complete solution,” but rather that he “merely sketched out one way of analyzing the varied relationship between character and gender” that could very well be considered incomplete (Cheng 29). This may relate back to something he says in a prior section: that some of the analysis “provides a lot of avenues for future research” (Cheng 24).
All in all, I really liked Cheng’s piece. The subject matter of the piece is something I’d like to continue to study and look into more; perhaps what interested me most was how going forward, the models Cheng used had more trouble predicting gender. I’m also curious about how one could theoretically conduct a similar study, but one that accommodates for first-person pieces and character. Certainly, Fleshing Out Models of Gender in English-Language Novels (1850 – 2000) will be something I think back to if I ever have to do research on a related topic.
In this blog post, I will summarize and review the article Exploring the linguistic landscape of geotagged social media content in urban environments by Tuomo Hiippala et al. The concept of virtual linguistic landscape was developed by Ivkovic and Lotherington (2009) to discuss multilingualism on the web. In their paper, Hiippala and his fellow researchers explore the virtual linguistic landscape of Senate Square in Helsinki, Finland, by analyzing the text of 117,418 Instagram posts that are geotagged to that location. I chose this paper because I have a passion for maps, geotagged storytelling, and exploring the relationship between physical, virtual, and literary space.
I divided my article according to the phases of text analysis illustrated in Nguyen et al, 2020 for ease of analysis. I joined the phases of Operationalization and Analysis in order to keep together the different measurements and their results.
The researchers used born digital data from Instagram posts, which that they collected using the platform’s API.
117,418 posts
74,051 unique users
Posted between 4 July 2013 and 11 February 2018, that is, over a period of 4.5 years.
Each post was geotagged to a POI (Point of Interest) located within a 150-m radius from the centre of the Senate Square in downtown Helsinki, Finland. The square is a celebrated landmark and was chosen for its likelihood of depicting a diverse virtual linguistic landscape.
The first consideration I have is of ethical nature: the researchers collected data from unsuspecting users, who did not give their explicit consent to the experiment. As we will see in the Operationalization phase, the researchers went even beyond analyzing the posts from Senate Square, which gets a little creepy.
The second issue, which I honestly didn’t think about until I re-read How we do things with words, is that of data quality. APIs are designed for commercial purposes, and this is likely to introduce biases in the data and into the research.
Data from Instagram comes with metadata, which include the geotagged position of the post, the day and time of publication, et cetera. Hiippala et al. used these metadata in their study, for example in their analysis to determine the evolution of the linguistic landscape over time.
In the data processing phase, the article mentions how researchers cleaned the data: “We then remove any words that begin with an @ symbol, which indicates a username”. This expression made me think that usernames were part of the data, even if only in the case of people citing others in their posts with the @ symbol. Luckily, the researchers did not share their data, but I find it quite unsettling that this sort of information is available for the taking.
The researchers define linguistic richness as the number of unique languages per day, and the number of singletons, that is, how many languages appear only once a day.
Linguistic diversity needs to account for both the number of languages observed and their relative proportions.
First of all, the researchers created a ground truth. They selected a random sample of sentences, and two annotators examined them to determine the language they’re written in. The, they evaluated the accuracy of several language identification frameworks against the ground truth (the human-made annotations) and examined whether their performance would improve by excluding sentences with a low character count.
After some tries, they concluded that the fastText library and its pretrained model provided superior performance compared to langid.py and CLD2 regardless of the character threshold.
Data was preprocessed to remove emojis and smileys, excessive punctuation, multilingual hashtags and usernames, and sentence-level code-switching, as you can see in the table below.
Preprocessing of the Instagram posts data to make it readable for the machine
Further preprocessing caused a reduction in the dataset amounting to a loss of 17.31% of the data. The result was a dataset of 90,353 sentences in eighty unique languages posted over 1,662 days for analysing temporal changes in the virtual linguistic landscape.
Supervised and Unsupervised Models
Hiippala and his colleagues used a mix of supervised and unsupervised models. First, they used a supervised model to individuate the language of the posts. Then, they decided to focus on posts written in English by Finnish users, and to apply an unsupervised topic model to explore their use of language. Data was then processed with methods from the fields of ecology and biology to measure the linguistic richness and diversity of the posts. Moreover, the researchers performed temporal analyses at various timescales to examine changes in the virtual linguistic landscape.
From the analysis of the sentence-level language distribution in the captions, researchers calculated the daily relative frequencies for the three most common languages— English, Finnish, and Russian—and the combined relative frequency for the remaining seventy-seven languages identified in the data (grouped together under the label ‘other’).
The Senate Square is a big tourist attraction, and it seems to be reflected in the fact that approximately half of the sentences are written in English. Moreover, Finland is a popular destination for Russians due to its proximity and accessibility, to the point where Finnish overtook Russian as the second most common language only in 2015. This might be explained by the fact that the decline of the Russian language coincides with the economic sanctions imposed on Russia due to the invasion of Ukraine, which caused the number of Russian tourists visiting Helsinki to dip in 2015 and 2016.
Hiippala and colleagues noticed that English seemed to be gaining most from the growing popularity of Instagram, being used as a lingua franca on social media. This led them to wonder who these English users were: how many non-native English speakers use this language on Instagram? And this is where things get a little creepy, in my opinion.
To figure out which users are writing their captions in English, the researchers retrieved the time and location of posts for up to thirty-three previous posts for each user. Then, they determined the likely country of origin of the users by retrieving the administrative region of each coordinate/timestamp pair in the location history, used the timestamps to determine the overall duration of user’s activity within each region, and recorded the region with the most activity.
I don’t know, for some reason I find it a little disturbing that researchers went “fishing” into the users’ previous social media posts to determine where they are really from. Ah, what we agree to in the “Terms of Service”, just to see some cat videos!
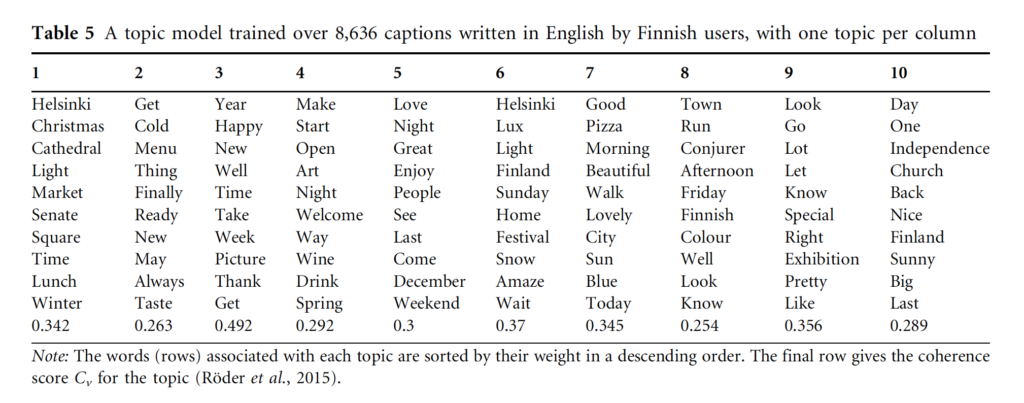
Anyway, this analysis revealed that Finnish users post nearly as much in English as in Finnish. To describe the content of the English posts by Finnish users, Hiippala and colleagues trained a topic model over monolingual English captions posted by users whose country of origin was estimated to be Finland. The data consisted of 8,636 captions with 5,552 unique words.
Results of the topic modeling
As you can see in the table, many topics have to do with the location, weather, leisure, and celebrations such as Christmas and New Year’s Eve (1 and 3) and the Lux light carnival (6). Many topics also feature words associated with a positive sentiment (3, 5–7,9, and 10). According to the researchers, these topics suggest that Finns use English to connect with international audiences, appraising the physical location and the activities associated with it in the virtual space.
The researchers used methods derived from ecology and biology to measure the linguistic richness and diversity of their linguistic landscape.
Linguistic Richness is defined as the number of unique languages per day, and the number of singletons, that is, how many languages appear only once a day. The fact that unique languages and singletons proceed in parallel suggests that smaller languages are driving the increase in linguistic richness.
Menhinick’s richness index: emphasizes the relationship between data volume and richness. The index reveals a decreasing trend over the 4.5 years. This trend suggests that despite increasing linguistic richness, driven by the increase in smaller languages, the virtual linguistic landscape is increasingly dominated by languages such as English, Finnish, and Russian
Berger–Parker dominance index: Measuring the diversity of the virtual linguistic landscape requires indices that account for both the number of languages observed and their relative proportions. One such index is the Berger–Parker dominance index, which gives the fraction of observations for the language with the most posts per day. Berger–Parker index suggests that the dominant languages are losing ground to smaller languages, showing a drop of thirty points during the 4.5 years, which suggests that the virtual linguistic landscape of the Senate Square is becoming increasingly diverse.
Shannon Entropy: captures the amount of information required to describe the degree of order/disorder in a system. The higher the degree of disorder (the variety of languages and their probability of occurrence), the more information is required to describe the system. The fact that the Shannon Entropy index peaked in 2017 led the researchers to conclude that the virtual linguistic landscape reached its maximum degree of diversity, with over eight languages on an average day.
The authors’ final considerations were:
The study confirmed the role of Senate Square both as a tourist attraction (high volume of posts by foreigners) and a beloved local landmark (high volume of posts by Finnish users). This fact aligns with Kellerman’s (2010) theory that the virtual space reflects characteristics of the physical space.
The richness and diversity of the virtual linguistic landscape of Senate Square seems to confirm Lee’s (2016) theory that user-generated social media content increases the potential for exposure to foreign languages. Instagram, in particular, allows locations to be displayed with multilingual names, aggregating content in different languages.
Review
What I liked about this project is that it mixes supervised and unsupervised machine learning in a seamless way, providing an analysis that makes a lot of sense and is easy to follow. I also appreciated that the research questions did not fall into obvious binary categorizations (especially in terms of gender), and instead measured linguistic richness and diversity without value judgements. Another detail I enjoyed is the fact that the researchers tied certain statistical results, like the decline of the use of Russian in 2015, to socio-political events. I honestly wished they had done more of this kind of analysis, which is not only interesting but might give fruitful insights on the state of the world.
Text analysis of social media still makes me a little uncomfortable, especially for a platform like Instagram, which is used mostly for personal content. However, I appreciate that the researchers did not try to create a network analysis of users or other models that resemble the commercial uses of social media data. Instead, they tried to detect the general content of the posts, specifically to understand how, why, and for what purpose Finnish users write their captions in English. I never thought of using social media to explore sociolinguistic geography, so this is definitely an effective and compelling use of machine learning.
Bibliography
Hiippala, Tuomo, et al. “Exploring the Linguistic Landscape of Geotagged Social Media Content in Urban Environments.” Digital Scholarship in the Humanities, vol. 34, no. 2, June 2019, pp. 290–309. EBSCOhost, doi:10.1093/llc/fqy049.
Ivkovic, Dejan, and Heather Lotherington. “Multilingualism in Cyberspace: Conceptualising the Virtual Linguistic Landscape.” International Journal of Multilingualism, vol. 6, no. 1, Taylor & Francis Group, 2009, pp. 17–36. cuny-gc.primo.exlibrisgroup.com, doi:10.1080/14790710802582436.
Kellerman, Aharon. “Mobile Broadband Services and the Availability of Instant Access to Cyberspace.” Environment and Planning. A, vol. 42, no. 12, SAGE Publications, Pion Ltd, London, Sage Publications, Inc, 2010, pp. 2990–3005. cuny-gc.primo.exlibrisgroup.com, doi:10.1068/a43283.
Lee, Carmen. “Multilingual Resources and Practices in Digital Communication.” The Routledge Handbook of Language and Digital Communication, Routledge, 2016, pp. 118-132. www.academia.edu, https://www.academia.edu/15252858/Multilingual_resources_and_practices_in_digital_communication.
For today’s class I chose the article Gender Dynamics and Critical Reception: A Study of Early 20th-century Book Reviews from The New York Times by Matthew J. Lavin. In this article, Lavin details his analysis of 2800 book reviews published in The New York Timesfrom the early 20th-century, employing multiple machine learning scenarios to explore how these book reviews furthered sexist outlooks on female authorship and “gendered norms for reading and readership.”
After collecting his data online from The New York Times, Lavin utilized a logistic regression model, where data is divided into train and test sets and then compared. In this experiment, the book reviews acted as the training set and a series of predictions acted as the test set. Using this model, Lavin investigated how well a logistic regression model could predict the gender of an author. Lavin employed several scenarios using the logistic regression model: first no terms were removed, then stop words were removed, then stop words, gender nouns, and titles removed, and finally stop words, gender nouns, titles, and common forenames removed. After each scenario, Lavin examined the top coefficients for what the model predicted as male and female writers. Scenario 1’s results generated an accuracy rate of 78%-90%. However, as gendered terms and other words are removed, accuracy begins to decrease. Through lemmatization, Lavin consolidates frequently used terms and categories based on the female and male coefficients found in the 4th and final scenario. Lavin uses the example lemma ‘child.’ This term is found in 700 reviews, notably 36% female labeled and only 24% male labeled.
Based on the results of the four scenarios, Lavin notes that most female labeled lemma coefficients tend to be related to domestic settings, marriage, and aesthetics, while male labeled lemma coefficients tend to be related to prestige, power, military and government. Moreover, Lavin notes that non-fiction is more associated with male writers, while fiction is more associated with female writers. This is notable as it relates to the topic of middlebrow literature and how often this type of literature is associated with ‘cheap fiction,’ sentimental themes, mediocrity, and “aimless, indolent and ardent femininity.” Lavin’s final thoughts asserted that the results of his analysis showed evidence that, “behind a veneer of neutrality, gender norms were being established, parameterized, and lined to taste-making.”
Final Thoughts:
The impact that reviews have in our modern culture is undeniable. Whether one is looking for a book to read or trying out a new restaurant, most know that reviews that be found online quickly and seamlessly. Negative reviews can make or break a business, and for things like movies and books, the opinions of self-proclaimed expert critics can have an immense impact on overall reception of the work. I found this article so interesting because I failed to consider the genesis of these kinds of reviews and how they could so negatively impact perception of certain types of writing, themes and authorship. I think this is a theme that could be further explored in modern reviews of books, television shows or movies; the results of modern reviews could be then compared to older reviews and see if gendered norms have changed or not over the years.
This article explores the impact early 20th-century book reviews in The New York Times had on gendering authors, reception landscapes of works associated with male and female authors, and the feminization of what was considered middlebrow literature.
Each of this week’s readings had something stick out to me above the rest of content in the text. The idea of technochauvinism, at least to me, is very intriguing, and was thus something I had in my head throughout my exploration of the texts. Admittedly, I read beyond the assigned pages in Chun’s piece, but if nothing else, this broadened my understanding of quite a few topics, technochauvinism included.
First, on the very first page of Wendy Chun’s Pattern Discrimination, she asks, quite simply, “what is recognition?” She then presents a thought-provoking comparison: the difficulty of a police officer hailing a single person on the street, compared to the difficulty of a police officer hailing a number of people equal to the number of bits traveling the internet per second (supposedly at the time of writing, 414 trillion bits) (Chun 1). In short, this demonstrates the necessity of pattern recognition, but it also sets a subtle precedent for what’s to come. Indeed, it was this comparison that led me to read beyond the assigned pages, as I saw it when I was first scrolling through the .pdf of the text. While it may simply be a product of the times, the usage of a police officer in the comparison is disturbingly fitting with the subjects presented later in the text, specifically in the realm of the “discrimination” mentioned in the title.
While Chun doesn’t directly discuss technochauvinism, much of what she writes does concern it, especially when examined with the previous comparison in mind. Essentially, a police officer is a human being, and thus is subject to emotion and human error. However, she regularly makes points about the problems with pattern recognition – for instance, about hermeneutics. Additionally, human beings are prone to bias, but Chun explicitly states that “objective analytics, devoid of any interpretation and thus of any bias, does not exist,” or to elaborate, even if a computer were able to make “superior,” unbiased analyses, upon being interpreted by a human being, they would immediately become biased (Chun 35). Even if the computer itself is unbiased, it does not matter, as the humans using the computer are biased.
On the subject of technochauvinism, Meredith Broussard’s Artificial Unintelligence: How Computers Misunderstand the World defines the term as the idea that technology is “always the solution” (Broussard 8). Broussard describes technochauvinism as a “flawed assumption,” a “red flag” (Broussard 7) and as something “often accompanied by fellow-traveler beliefs such as Ayn Randian meritocracy,” specifically citing the related, flawed idea that computers being more “‘objective'” due to their ability to reduce information down to relatively basic math (Broussard 8). Broussard’s discussions of perceived objectivity of computers have a significant amount of clear overlap with Chun’s, to be sure. Similar to how Broussard tells about how her friend’s assumptions about technological superiority stuck with her, the very term “technochauvinism” has stuck with me from the first time I heard it in class some time back.
Broussard refutes the idea that computers are better due to some form of “objectivity” through showing by way of example that computers constructed by humans capable of error (that is, all humans) are subject to the errors and biases of said humans. She writes that a “problem is usually in the machine somewhere” as a result of “poorly designed or tested code” – in other words, that the problem with a computer is the fault of the human that designed it (Broussard 8). One can say that a computer is powerfully “objective” as much as one wants, but even if this is the case, the “objective” data a computer produces is rendered moot when viewed by a human being with subjective bias or the capacity for error (again, all humans) and even then, this is assuming that this “objective” data is not influenced by computer errors (in fact, human in origin).
I want to bring to mind the idea of the platonic ideal, briefly, as I’ve noticed an interesting connection to it. Through the eyes of a technochauvinist, through a technochauvinist lens, a computer is for most intents and purposes something more objective, and thus powerful, than any human: something a human cannot replicate the function of perfectly, similar to how a human cannot perfectly reproduce a platonic ideal. If one claims a computer is a source of perfectly objective information, when that information is interpreted or reproduced by a human, it stops being perfectly objective, just as how humans attempting to replicating a platonic ideal create content further from it. This has made me wonder about the connections between computers, objectivity, technochauvinism, derivative content (parody, pastche, etc.), and rhizomatics as a whole.
This is a Post.Instructors often post announcements, assignments, and discussion questions for for students to comment. Some instructors have students post assignments. Posts are listed on the “Posts” page with the newest at the top.
PostComments are turned on by default(see Home for information on Comments).
Add/Remove a password from this post from the Post Editor > Visibility > Edit > Password Protected.
Add/Edit/Delete a post from Dashboard > Posts
Need help with the Commons?
Email us at [email protected] so we can respond to your questions and requests. Please email from your CUNY email address if possible. Or visit our help site for more information:


![A list of 8 passages of preprocessing the data from the Instagram posts. Text:
1 The original caption includes hashtags, user mentions, and smileys and emojis
Great weather in Helsinki!!! On holiday with @username.:-) #helsinki #visitfinland
2 We begin by replacing any line breaks with whitespace and convert the emojis into their corresponding emoji shortcodes,
which are wrapped in colons
Great weather in Helsinki!!! On holiday with @username.:-) #helsinki #visitfinland:nerd_
face_&_sunny_&_passenger_ship:
3 The colons make finding the emojis easy using a regular expression, which we then apply to remove them
Great weather in Helsinki!!! On holiday with @username.:-) #helsinki #visitfinland
4 We then remove any words that begin with an @ symbol, which indicates a username
Great weather in Helsinki!!! On holiday with:-)#helsinki #visitfinland
5 Next, we remove any hashtags, that is, any words beginning with a #
Great weather in Helsinki!!! On holiday with:-)
6 Any remaining non-alphanumeric words in the caption, such as the smiley:-) are then removed using a regular expression
Great weather in Helsinki!!! On holiday with
7 Longer sequences of exclamation or question marks (e.g. !!!), full stops, and other kinds of punctuation are shortened to
just one of each character (e.g. !)
Great weather in Helsinki! On holiday with
8 These sequences can confuse the Punkt sentence tokenizer (Kiss and Strunk, 2006), which outputs a Python list
containing sentence tokens. These tokens are then fed to the language identification frameworks one at a time
[”Great weather in Helsinki!”, ”On holiday with”]](https://femethods2020.commons.gc.cuny.edu/files/2020/11/data-preprocessing-1024x456.png)